Edge computing alleviates the dilemma of insufficient abilities in mobile devices as well as great
latency and bandwidth pressure in remote cloud. Prior approaches that dispatch jobs to a single edge
cloud are prone to cause task accumulation and excessive latency due to the uncertain workload and
limited resources of edge servers. Offloading tasks to lightly-loaded neighbors, which are multiple
hops away, alleviates the dilemma but increases transmission cost and security risks. Consequently,
performing job dispatching to realize the trade-off between computing latency, energy consumption
and security while ensuring users’ Quality of Service (QoS) is a complicated challenge.
Static model-based algorithms are inapplicable in dynamical edge environment due to the long
decision-making time and significant computational overhead. While deep learning methods such
as deep reinforcement learning (DRL) make decisions in a global view and adapts to the variations
in edge. Besides, graph neural networks (GNN) effectively transmit node information and extracts
features over graphs, which are naturally fit with directed acyclic graph (DAG) jobs. Some existing
works using deep learning methods don’t take the workload of servers and data security risks during
offloading into consideration.
The secure collaborative job dispatching in edge can be defined as: for each subtask in the job, we
make a dispatching decision about its execution location (the destination edge server to perform this
task and the corresponding transmit path), while achieving a trade-off between computing latency
and offload cost to ensure users’ QoS and service providers’ profits. Tasks are executed on a certain
edge server either in the local edge cloud or a non-local one beyond several hops.


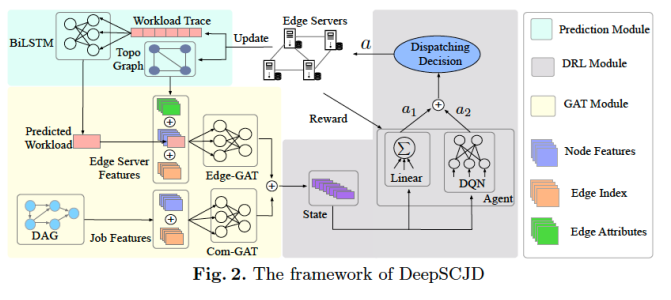
In this paper, we propose an online deep learning-based secure collaborative job dispatching model
(DeepSCJD) in edge computing. The framework is as follows: the historical data of resource
utilization of edge servers is input into the Bi-directional Long Short-Term Memory (BiLSTM)
model to predict the workload situation at the next moment, which is regarded as one of dimensions
of servers’ characteristics. In the meantime, we process the network topology to obtain initial
features of the edge servers. The Graph Attention Networks (GAT), which is one kind of GNN
networks, extract and aggregate the features of jobs and edge servers separately, deriving highdimensional abstract ones. These two outputs are concated to compose the current state. In DRL, a
two-branch agent involving a linear and DQN branch makes job dispatching decisions.
Next, tasks are offloaded and performed on destination edge servers to generate a reward. The agent
detects this reward to adjust the dispatching behavior at the next step. Moreover, we update the
current load of edge servers and the time window of BiLSTM slides one bit backward. The new
workload is applied to the next round prediction. The occupancy conditions of CPU, Memory and
Disk of edge servers also vary, resulting in server attributes modifying accordingly.
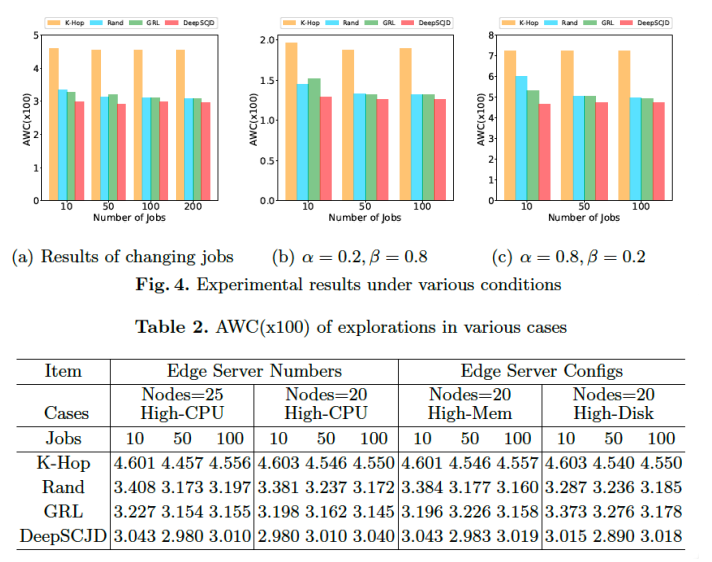
We select some traditional baselines including K-Hop, which select the edge server randomly that
is K hops away, and Rand method, which randomly selects a server in global topo map. A deep
learning approach GRL is also regarded as comparation, which utilizes gradual convolutional
network and DRL make job dispatching decisions. We test our model under various conditions, i.e.
changing the number of jobs, the number of edge cloud nodes, the weight parameters in objective
function and the configurations of edge servers. Experiments on real-world data sets demonstrate
the efficiency of proposed model and its superiority over traditional and state-of-the-art baselines,
reaching the maximum average performance improvement of 54.16% relative to K-Hop. Extensive
evaluations manifest the generalization of our model under various conditions.
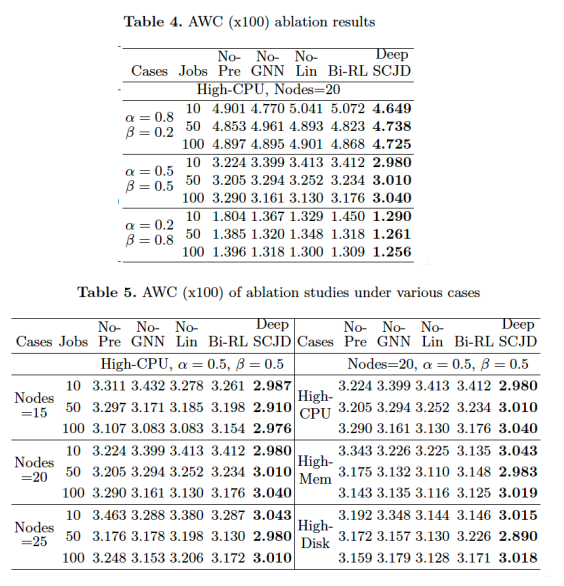
Ablation experiments are conducted to verify the effectiveness of each submodule in our model,
and we compared the model which remove some certain parts in the proposed model with
DeepSCJD itself. We see that each sub-module has a performance improvement for the final
decisions in all cases.
Authors
 Zhaoyang Yu received the B.E. degree from College of Computer and Control Engineering in Nankai University (NKU), Tianjin, China, in 2018. She is currently pursuing the Ph.D. degree with the Department of Computer Science in NKU. Her research interests include mobile edge computing, task scheduling, resource management and deep learning.
Zhaoyang Yu received the B.E. degree from College of Computer and Control Engineering in Nankai University (NKU), Tianjin, China, in 2018. She is currently pursuing the Ph.D. degree with the Department of Computer Science in NKU. Her research interests include mobile edge computing, task scheduling, resource management and deep learning.
 Sinong Zhao received the B.E. degree from Honors College in Northwestern Polytechnical University, Xi’an, China, in 2018. She is currently working towards his Ph.D. at Nankai University. Her research interests include machine learning, data mining, and anomaly detection.
Sinong Zhao received the B.E. degree from Honors College in Northwestern Polytechnical University, Xi’an, China, in 2018. She is currently working towards his Ph.D. at Nankai University. Her research interests include machine learning, data mining, and anomaly detection.
 Tongtong Su received the B.S. degree in software engineering from the Tianjin Normal University, Tianjin, China, in 2016, and the M.S. degree from the School of Computer and Information Engineering, Tianjin Normal University, Tianjin, China, in 2019. He is currently pursuing the Ph.D. degree with the College of Computer Science, Nankai University, Tianjin, China. His research interests include distributed deep learning, computer vision, and model compression.
Tongtong Su received the B.S. degree in software engineering from the Tianjin Normal University, Tianjin, China, in 2016, and the M.S. degree from the School of Computer and Information Engineering, Tianjin Normal University, Tianjin, China, in 2019. He is currently pursuing the Ph.D. degree with the College of Computer Science, Nankai University, Tianjin, China. His research interests include distributed deep learning, computer vision, and model compression.
 Wenwen Liu received her B.Sc. and M.Sc. degrees from the School of Computer Science and Technology, Tiangong University, Tianjin, China, in 2013 and 2016, respectively. She is currently pursuing the Ph.D. degree with the Department of Computer Science in NanKai University. Her research interests include machine learning, intelligent edge computing and wireless networks.
Wenwen Liu received her B.Sc. and M.Sc. degrees from the School of Computer Science and Technology, Tiangong University, Tianjin, China, in 2013 and 2016, respectively. She is currently pursuing the Ph.D. degree with the Department of Computer Science in NanKai University. Her research interests include machine learning, intelligent edge computing and wireless networks.
 Xiaoguang Liu (Member, IEEE) received his B.Sc., M.Sc., and Ph.D. degrees in computer science from Nankai University, Tianjin, China, in 1996, 1999, and 2002, respectively. He is currently a professor at the Department of Computer Science and Information Security, Nankai University. His research interests include search engines, storage systems, and GPU computing.
Xiaoguang Liu (Member, IEEE) received his B.Sc., M.Sc., and Ph.D. degrees in computer science from Nankai University, Tianjin, China, in 1996, 1999, and 2002, respectively. He is currently a professor at the Department of Computer Science and Information Security, Nankai University. His research interests include search engines, storage systems, and GPU computing.
 Gang Wang (Member, IEEE) received his B.Sc., M.Sc., and Ph.D.\ degrees in computer science from Nankai University, Tianjin, China, in 1996, 1999 and 2002, respectively. He is currently a professor at the Department of Computer Science and Information Security, Nankai University. His research interests include parallel computing, machine learning, storage systems, computer vision, and big data.
Gang Wang (Member, IEEE) received his B.Sc., M.Sc., and Ph.D.\ degrees in computer science from Nankai University, Tianjin, China, in 1996, 1999 and 2002, respectively. He is currently a professor at the Department of Computer Science and Information Security, Nankai University. His research interests include parallel computing, machine learning, storage systems, computer vision, and big data.
 Dr. Zehua Wang received his Ph.D. degree from The University of British Columbia (UBC), Vancouver in 2016 and was a Postdoctoral Research Fellow in the Wireless Networks and Mobile Systems (WiNMoS) Laboratory directed by Prof. Victor C.M. Leung from 2017 to 2018. He is now an Adjunct Professor in the Department of Electrical and Computer Engineering at UBC, a core-faculty member of Blockchain@UBC, and a Mentor of entrepreneurship@UBC. He is interested in applying the cryptography, zero-knowledge proof, and game theories in the protocol designs and Web3 applications. His research focuses on improving the synergy and security of the decentralized multi-agent systems. The major research projects that he is currently working on include blockchain and smart contract security, applications of zero-knowledge proof in blockchain, and decentralized privacy-preserving machine learning.
Dr. Zehua Wang received his Ph.D. degree from The University of British Columbia (UBC), Vancouver in 2016 and was a Postdoctoral Research Fellow in the Wireless Networks and Mobile Systems (WiNMoS) Laboratory directed by Prof. Victor C.M. Leung from 2017 to 2018. He is now an Adjunct Professor in the Department of Electrical and Computer Engineering at UBC, a core-faculty member of Blockchain@UBC, and a Mentor of entrepreneurship@UBC. He is interested in applying the cryptography, zero-knowledge proof, and game theories in the protocol designs and Web3 applications. His research focuses on improving the synergy and security of the decentralized multi-agent systems. The major research projects that he is currently working on include blockchain and smart contract security, applications of zero-knowledge proof in blockchain, and decentralized privacy-preserving machine learning.
 Victor C.M. Leung is PEng, PhD, FIEEE, FRSC, FEIC, FCAE, Professor Emeritus, Communications Group, Director, Wireless Networks and Mobile Systems (WiNMoS) Laboratory, Dept. of Electrical and Computer Engineering. His research interests are in the area of telecommunications and computer communications networking. The scope of the research includes design, evaluation, and analysis of network architectures, protocols, and network management, control, and internetworking strategies for reliable, efficient, and cost effective communications.
Victor C.M. Leung is PEng, PhD, FIEEE, FRSC, FEIC, FCAE, Professor Emeritus, Communications Group, Director, Wireless Networks and Mobile Systems (WiNMoS) Laboratory, Dept. of Electrical and Computer Engineering. His research interests are in the area of telecommunications and computer communications networking. The scope of the research includes design, evaluation, and analysis of network architectures, protocols, and network management, control, and internetworking strategies for reliable, efficient, and cost effective communications.